From Binary to Data Structures
Posted
by Cédric Menzi
on Geeks with Blogs
See other posts from Geeks with Blogs
or by Cédric Menzi
Published on Sun, 07 Mar 2010 13:07:47 GMT
Indexed on
2010/03/07
23:28 UTC
Read the original article
Hit count: 2150
Table of Contents
- Introduction
- PE file format and COFF header
- BaseCoffReader
- Byte4ByteCoffReader
- UnsafeCoffReader
- ManagedCoffReader
- Conclusion
- History
This article is also available on CodeProject
Introduction
Sometimes, you want to parse well-formed binary data and bring it into your objects to do some dirty stuff with it.
In the Windows world most data structures are stored in special binary format. Either we call a WinApi function or we want to read from special files like images, spool files, executables or may be the previously announced Outlook Personal Folders File.
Most specifications for these files can be found on the MSDN Libarary: Open Specification
In my example, we are going to get the COFF (Common Object File Format) file header from a PE (Portable Executable). The exact specification can be found here: PECOFF
PE file format and COFF header
Before we start we need to know how this file is formatted. The following figure shows an overview of the Microsoft PE executable format.
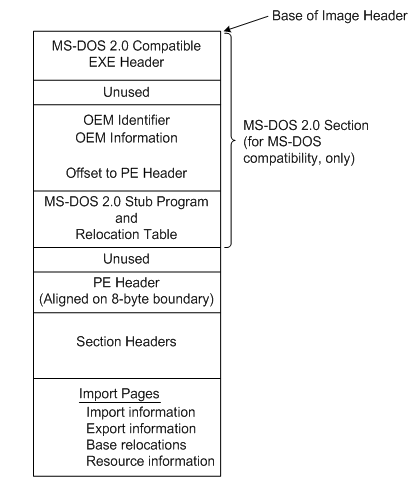 Source: Microsoft
Source: Microsoft
Our goal is to get the PE header. As we can see, the image starts with a MS-DOS 2.0 header with is not important for us. From the documentation we can read "...After the MS DOS stub, at the file offset specified at offset 0x3c, is a 4-byte...".
With this information we know our reader has to jump to location 0x3c and read the offset to the signature. The signature is always 4 bytes that ensures that the image is a PE file. The signature is: PE\0\0.
To prove this we first seek to the offset 0x3c, read if the file consist the signature.
So we need to declare some constants, because we do not want magic numbers.
private const int PeSignatureOffsetLocation = 0x3c;
private const int PeSignatureSize = 4;
private const string PeSignatureContent = "PE";
Then a method for moving the reader to the correct location to read the offset of signature. With this method we always move the underlining Stream of the BinaryReader to the start location of the PE signature.
private void SeekToPeSignature(BinaryReader br) {
// seek to the offset for the PE signagure
br.BaseStream.Seek(PeSignatureOffsetLocation, SeekOrigin.Begin);
// read the offset
int offsetToPeSig = br.ReadInt32();
// seek to the start of the PE signature
br.BaseStream.Seek(offsetToPeSig, SeekOrigin.Begin);
}
Now, we can check if it is a valid PE image by reading of the next 4 byte contains the content PE.
private bool IsValidPeSignature(BinaryReader br) {
// read 4 bytes to get the PE signature
byte[] peSigBytes = br.ReadBytes(PeSignatureSize);
// convert it to a string and trim \0 at the end of the content
string peContent = Encoding.Default.GetString(peSigBytes).TrimEnd('\0');
// check if PE is in the content
return peContent.Equals(PeSignatureContent);
}
With this basic functionality we have a good base reader class to try the different methods of parsing the COFF file header.
COFF file header
The COFF header has the following structure:
| Offset | Size | Field |
| 0 | 2 | Machine |
| 2 | 2 | NumberOfSections |
| 4 | 4 | TimeDateStamp |
| 8 | 4 | PointerToSymbolTable |
| 12 | 4 | NumberOfSymbols |
| 16 | 2 | SizeOfOptionalHeader |
| 18 | 2 | Characteristics |
If we translate this table to code, we get something like this:
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Unicode)]
public struct CoffHeader {
public MachineType Machine;
public ushort NumberOfSections;
public uint TimeDateStamp;
public uint PointerToSymbolTable;
public uint NumberOfSymbols;
public ushort SizeOfOptionalHeader;
public Characteristic Characteristics;
}
BaseCoffReader
All readers do the same thing, so we go to the patterns library in our head and see that Strategy pattern or Template method pattern is sticked out in the bookshelf.
I have decided to take the template method pattern in this case, because the Parse() should handle the IO for all implementations and the concrete parsing should done in its derived classes.
public CoffHeader Parse() {
using (var br = new BinaryReader(File.Open(_fileName, FileMode.Open, FileAccess.Read, FileShare.Read))) {
SeekToPeSignature(br);
if (!IsValidPeSignature(br)) {
throw new BadImageFormatException();
}
return ParseInternal(br);
}
}
protected abstract CoffHeader ParseInternal(BinaryReader br);
First we open the BinaryReader, seek to the PE signature then we check if it contains a valid PE signature and rest is done by the derived implementations.
Byte4ByteCoffReader
The first solution is using the BinaryReader. It is the general way to get the data. We only need to know which order, which data-type and its size. If we read byte for byte we could comment out the first line in the CoffHeader structure, because we have control about the order of the member assignment.
protected override CoffHeader ParseInternal(BinaryReader br) {
CoffHeader coff = new CoffHeader();
coff.Machine = (MachineType)br.ReadInt16();
coff.NumberOfSections = (ushort)br.ReadInt16();
coff.TimeDateStamp = br.ReadUInt32();
coff.PointerToSymbolTable = br.ReadUInt32();
coff.NumberOfSymbols = br.ReadUInt32();
coff.SizeOfOptionalHeader = (ushort)br.ReadInt16();
coff.Characteristics = (Characteristic)br.ReadInt16();
return coff;
}
If the structure is as short as the COFF header here and the specification will never changed, there is probably no reason to change the strategy. But if a data-type will be changed, a new member will be added or ordering of member will be changed the maintenance costs of this method are very high.
UnsafeCoffReader
Another way to bring the data into this structure is using a "magically" unsafe trick. As above, we know the layout and order of the data structure. Now, we need the StructLayout attribute, because we have to ensure that the .NET Runtime allocates the structure in the same order as it is specified in the source code. We also need to enable "Allow unsafe code (/unsafe)" in the project's build properties.
Then we need to add the following constructor to the CoffHeader structure.
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Unicode)]
public struct CoffHeader {
public CoffHeader(byte[] data) {
unsafe {
fixed (byte* packet = &data[0]) {
this = *(CoffHeader*)packet;
}
}
}
}
The "magic" trick is in the statement: this = *(CoffHeader*)packet;. What happens here? We have a fixed size of data somewhere in the memory and because a struct in C# is a value-type, the assignment operator = copies the whole data of the structure and not only the reference.
To fill the structure with data, we need to pass the data as bytes into the CoffHeader structure. This can be achieved by reading the exact size of the structure from the PE file.
protected override CoffHeader ParseInternal(BinaryReader br) {
return new CoffHeader(br.ReadBytes(Marshal.SizeOf(typeof(CoffHeader))));
}
This solution is the fastest way to parse the data and bring it into the structure, but it is unsafe and it could introduce some security and stability risks.
ManagedCoffReader
In this solution we are using the same approach of the structure assignment as above. But we need to replace the unsafe part in the constructor with the following managed part:
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Unicode)]
public struct CoffHeader {
public CoffHeader(byte[] data) {
IntPtr coffPtr = IntPtr.Zero;
try {
int size = Marshal.SizeOf(typeof(CoffHeader));
coffPtr = Marshal.AllocHGlobal(size);
Marshal.Copy(data, 0, coffPtr, size);
this = (CoffHeader)Marshal.PtrToStructure(coffPtr, typeof(CoffHeader));
} finally {
Marshal.FreeHGlobal(coffPtr);
}
}
}
Conclusion
We saw that we can parse well-formed binary data to our data structures using different approaches. The first is probably the clearest way, because we know each member and its size and ordering and we have control about the reading the data for each member. But if add member or the structure is going change by some reason, we need to change the reader.
The two other solutions use the approach of the structure assignment. In the unsafe implementation we need to compile the project with the /unsafe option. We increase the performance, but we get some security risks.
© Geeks with Blogs or respective owner