BizTalk: History of one project architecture
Posted
by Leonid Ganeline
on Geeks with Blogs
See other posts from Geeks with Blogs
or by Leonid Ganeline
Published on Fri, 24 Dec 2010 21:26:31 GMT
Indexed on
2010/12/24
21:54 UTC
Read the original article
Hit count: 393
Filed under:
"In the beginning God made heaven and earth. Then he started to integrate." At the very start was the requirement: integrate two working systems.
Small digging up: It was one system. It was good but IT guys want to change it to the new one, much better, chipper, more flexible, and more progressive in technologies, more suitable for the future, for the faster world and hungry competitors.
One thing. One small, little thing. We cannot turn off the old system (call it A, because it was the first), turn on the new one (call it B, because it is second but not the last one). The A has a hundreds users all across a country, they must study B. A still has a lot nice custom features, home-made features that cannot disappear. These features have to be moved to the B and it is a long process, months and months of redevelopment.
So, the decision was simple. Let’s move not jump, let’s both systems working side-by-side several months. In this time we could teach the users and move all custom A’s special functionality to B.
That automatically means both systems should work side-by-side all these months and use the same data. Data in A and B must be in sync. That’s how the integration projects get birth.
Moreover, the specific of the user tasks requires the both systems must be in sync in real-time. Nightly synchronization is not working, absolutely.
First draft

The first draft seems simple. Both systems keep data in SQL databases. When data changes, the Create, Update, Delete operations performed on the data, and the sync process could be started. The obvious decision is to use triggers on tables. When we are talking about data, we are talking about several entities. For example, Orders and Items [in Orders].
We decided to use the BizTalk Server to synchronize systems. Why it was chosen is another story.
Second draft
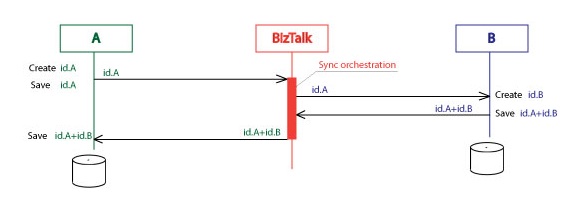
Let’s take an example how it works in more details.
1. User creates a new entity in the A system. This fires an insert trigger on the entity table. Trigger has to pass the message “Entity created”. This message includes all attributes of the new entity, but I focused on the Id of this entity in the A system. Notation for this message is id.A. System A sends id.A to the BizTalk Server.
2. BizTalk transforms id.A to the format of the system B. This is easiest part and I will not focus on this kind of transformations in the following text. The message on the picture is still id.A but it is in slightly different format, that’s why it is changing in color. BizTalk sends id.A to the system B.
3. The system B creates the entity on its side. But it uses different id-s for entities, these id-s are id.B. System B saves id.A+id.B. System B sends the message id.A+id.B back to the BizTalk.
4. BizTalk sends the message id.A+id.B to the system A.
5. System A saves id.A+id.B.
Why both id-s should be saved on both systems? It was one of the next requirements. Users of both systems have to know the systems are in sync or not in sync. Users working with the entity on the system A can see the id.B and use it to switch to the system B and work there with the copy of the same entity. The decision was to store the pairs of entity id-s on both sides. If there is only one id, the entities are not in sync yet (for the Create operation).
Third draft
Next problem was the reliability of the synchronization. The synchronizing process can be interrupted on each step, when message goes through the wires. It can be communication problem, timeout, temporary shutdown one of the systems, the second system cannot be synchronized by some internal reason. There were several potential problems that prevented from enclosing the whole synchronization process in one transaction.
Decision was to restart the whole sync process if it was not finished (in case of the error). For this purpose was created an additional service. Let’s call it the Resync service.
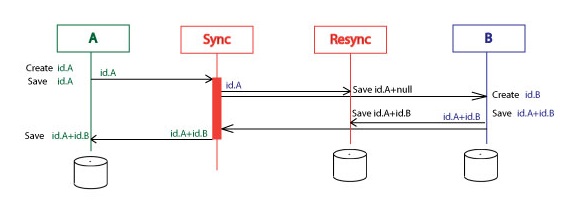
We still keep the id pairs in both systems, but only for the fast access not for the synchronization process. For the synchronizing these id-s now are kept in one main place, in the Resync service database.
The Resync service keeps record as:
· Id.A
· Id.B
· Entity.Type
· Operation (Create, Update, Delete)
· IsSyncStarted (true/false)
· IsSyncFinished (true/false0
The example now looks like:
1. System A creates id.A. id.A is saved on the A. Id.A is sent to the BizTalk.
2. BizTalk sends id.A to the Resync and to the B. id.A is saved on the Resync.
3. System B creates id.B. id.A+id.B are saved on the B. id.A+id.B are sent to the BizTalk.
4. BizTalk sends id.A+id.B to the Resync and to the A. id.A+id.B are saved on the Resync.
5. id.A+id.B are saved on the B.
Resync changes the IsSyncStarted and IsSyncFinished flags accordingly.
The Resync service implements three main methods:
· Save (id.A, Entity.Type, Operation)
· Save (id.A, id.B, Entity.Type, Operation)
· Resync ()
Two Save() are used to save id-s to the service storage. See in the above example, in 2 and 4 steps.
What about the Resync()? It is the method that finishes the interrupted synchronization processes. If Save() is started by the trigger event, the Resync() is working as an independent process. It periodically scans the Resync storage to find out “unfinished” records. Then it restarts the synchronization processes. It tries to synchronize them several times then gives up.
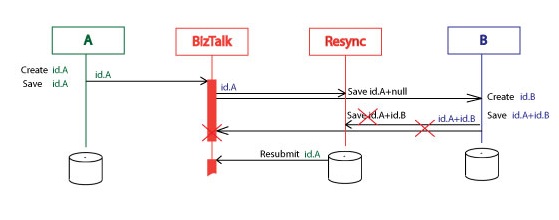
One more thing, both systems A and B must tolerate duplicates of one synchronizing process. Say on the step 3 the system B was not able to send id.A+id.B back. The Resync service must restart the synchronization process that will send the id.A to B second time. In this case system B must just send back again also created id.A+id.B pair without errors. That means “tolerate duplicates”.
Fourth draft
Next draft was created only because of the aesthetics. As it always happens, aesthetics gave significant performance gain to the whole system.
First was the stupid question. Why do we need this additional service with special database? Can we just master the BizTalk to do something like this Resync() does?
So the Resync orchestration is doing the same thing as the Resync service.
It is started by the Id.A and finished by the id.A+id.B message. The first works as a Start message, the second works as a Finish message.
It is started by the Id.A and finished by the id.A+id.B message. The first works as a Start message, the second works as a Finish message.
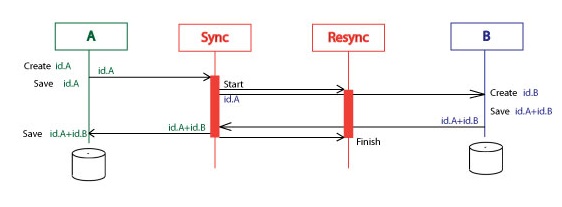
Here is a diagram the whole process without errors. It is pretty straightforward.
The Resync orchestration is waiting for the Finish message specific period of time then resubmits the Id.A message. It resubmits the Id.A message specific number of times then gives up and gets suspended. It can be resubmitted then it starts the whole process again:
waiting [, resubmitting [, get suspended]], finishing.
waiting [, resubmitting [, get suspended]], finishing.
Tuning up
The Resync orchestration resubmits the id.A message with special “Resubmitted” flag. The subscription filter on the Resync orchestration includes predicate as (Resubmit_Flag != “Resubmitted”). That means only the first Sync orchestration starts the Resync orchestration. Other Sync orchestration instantiated by the resubmitting can finish this Resync orchestration but cannot start another instance of the Resync
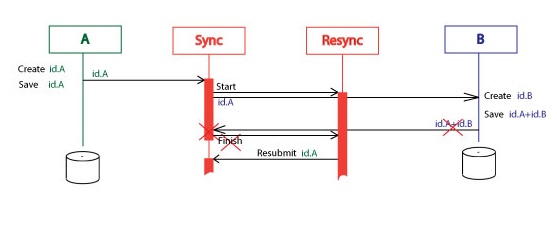
Here is a diagram where system B was inaccessible for some period of time. The Resync orchestration resubmitted the id.A two times. Then system B got the response the id.A+id.B and this finished the Resync service execution.
What is interesting about this, there were submitted several identical id.A messages and only one id.A+id.B message. Because of this, the system B and the Resync must tolerate the duplicate messages. We also told about this requirement for the system B. Now the same requirement is for the Resunc.
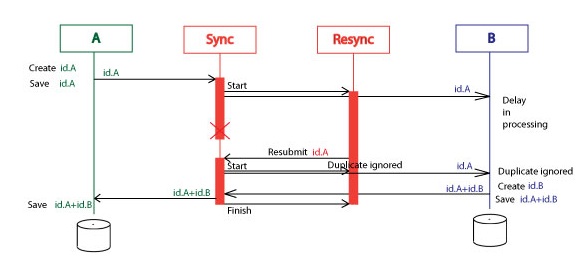
Let’s assume the system B was very slow in the first response and the Resync service had time to resubmit two id.A messages. System B responded not, as it was in previous case, with one id.A+id.B but with two id.A+id.B messages.
First of them finished the Resync execution for the id.A. What about the second id.A+id.B? Where it goes? So, we have to add one more internal requirement. The whole solution must tolerate many identical id.A+id.B messages. It is easy task with the BizTalk. I added the “SinkExtraMessages” subscriber (orchestration with one receive shape), that just get these messages and do nothing.
First of them finished the Resync execution for the id.A. What about the second id.A+id.B? Where it goes? So, we have to add one more internal requirement. The whole solution must tolerate many identical id.A+id.B messages. It is easy task with the BizTalk. I added the “SinkExtraMessages” subscriber (orchestration with one receive shape), that just get these messages and do nothing.
Real design
Real architecture is much more complex and interesting.
In reality each system can submit several id.A almost simultaneously and completely unordered.
There are not only the “Create entity” operation but the Update and Delete operations. And these operations relate each other. Say the Update operation after Delete means not the same as Update after Create.
In reality there are entities related each other. Say the Order and Order Items. Change on one of it could start the series of the operations on another. Moreover, the system internals are the “black boxes” and we cannot predict the exact content and order of the operation series.
It worth to say, I had to spend a time to manage the zombie message problems. The zombies are still here, but this is not a problem now. And this is another story.
What is interesting in the last design? One orchestration works to help another to be more reliable. Why two orchestration design is more reliable, isn’t it something strange? The Synch orchestration takes all the message exchange between systems, here is the area where most of the errors could happen. The Resync orchestration sends and receives messages only within the BizTalk server.
Is there another design? Sure. All Resync functionality could be implemented inside the Sync orchestration. Hey guys, some other ideas?
© Geeks with Blogs or respective owner